Training Tab
The training tab is used to train the defined model leveraging prepared data.
Icons | Description |
|---|---|
 | Add Training Formulation Setup |
 | Duplicate Training Formulation Setup |
 | Remove Training Formulation Setup or Training Results |
 | Start Model Training (as configured) |
 | Edit Training Result (open result pop-up or rename/label a results) |
 | Apply Training Result to Current Model (current model is exported as calc script) |
 | Undo last Training Result Applied to Current Model |
Model Training Formulation Options
Four training formulations are supported in Data Explorer today. For most data training problems Stochastic Decent algorithm (stochastic gradient descent) is generally useful and trains well. Unconstrained nonlinear Solver is a good secondary alternative, if Stochastic Descent does not train well and if neither of these options trains well your problem may be poorly formulated, which implies there's poor correlation between selected input variables and the output target on rows selected for training.
Linear Target Ridge Regression can be very useful if you know the system of interest is a linear relationship. The Linear Ridge Residual regression assumes a linear relationship with a custom training target that is represented in the form of a set of Residual Equations.
ANN Model Training Window - Stochastic Decent Algorithm
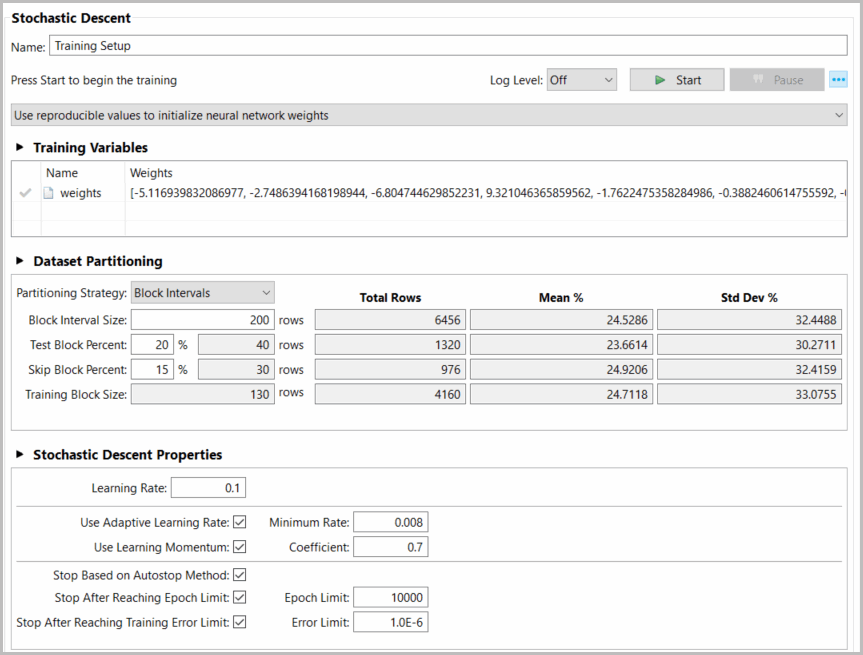
Immediately after defining a Training Setup its configuration window opens automatically. Setup Name may be modified for clearer identification, particularly useful if multiple setups are being used. Model starting parameters may be initialized with three options:
- Use reproducible values to initialize training. With this option each time a user starts training its starting position will be initialized to the same conditions based on variable statistics from the model definition tab. This can be useful when reproducing training is of interest.
- Use current/nominal values to initialize training. With this option each time model parameters are applied to the model, training will resume from that last, accepted starting conditions.
- Use random values to initialize training. With this option each training execution will start from different random initial parameters, which can lead to higher model accuracy by unique starting conditions.
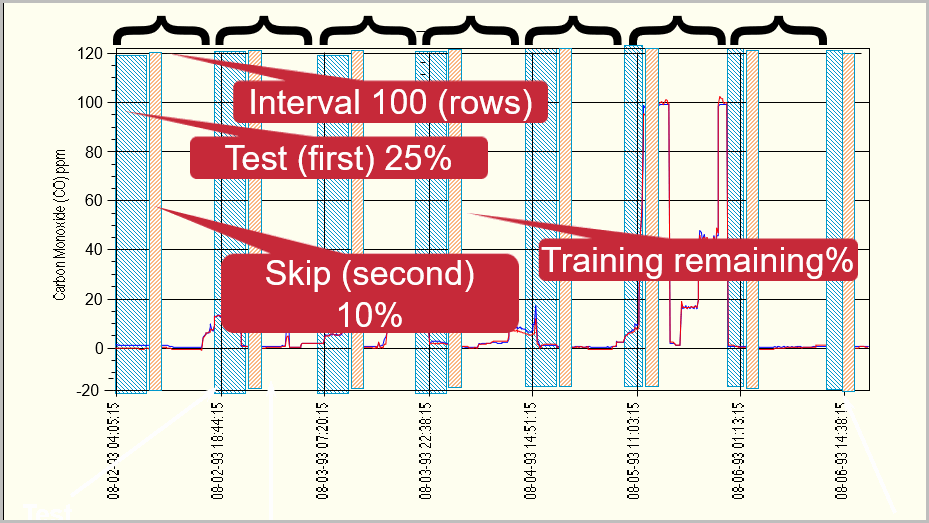
Partitioning is setup to segment the selected, prepared training data in blocks of data, divided into training data, testing data (used to select best training results) and skipped data (unused in training and useful to validate or forecast model accuracy on future unavailable data). Block interval size (number of rows), and Test and Skip percentages on each (rounded up) are adjustable. The user may want to adjust these parameters to target reasonably similar statistics as presented for mean and standard deviation (shown in percent of data range).
Training Data Segmentation
If the user opens the Stochastic Decent expert, , parameters specific parameters may be adjusted. This is generally not required but are available for use by expert users. Once training is setup as desired, training can be started by either
, parameters specific parameters may be adjusted. This is generally not required but are available for use by expert users. Once training is setup as desired, training can be started by either  icon. In general training will stop automatically and can be observed, paused or allowed to run to detected completion. To debug issues, log levels can be adjusted and will be updated on the Console log along with in
icon. In general training will stop automatically and can be observed, paused or allowed to run to detected completion. To debug issues, log levels can be adjusted and will be updated on the Console log along with in
, parameters specific parameters may be adjusted. This is generally not required but are available for use by expert users. Once training is setup as desired, training can be started by either icon. In general training will stop automatically and can be observed, paused or allowed to run to detected completion. To debug issues, log levels can be adjusted and will be updated on the Console log along with in C:\Program Files\Rockwell Software\FactoryTalk Analytics Data Explorer\4.5\workspace\.metadata \ModelTraining.log
. Note also that training problems may be presented in the Problems View.
Training Result Information
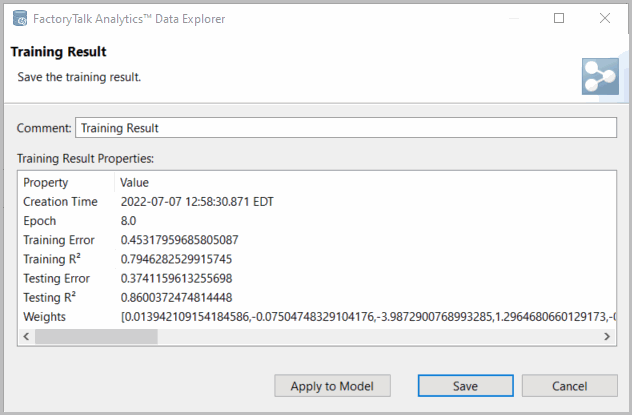
On completion and selection of the 'best' result (determined by the best Testing R2), the result is presented. Note if you wish to save a result for later, now or at a later review users may label training results of interest in the Comment field. The following information is provided:
- Time model was created (training completion time)
- Epoch: how many times the entire dataset was run through with the training algorithm to determine this model result.
- Training and Testing error - normalized mean model percent error for Training or Testing data segments.
- Training and Testing R2, or coefficient of determination or measure of fit (1.0 is perfect with zero error).
- Weights (for ANN) or User identified training Coefficients (for equation-based) models, shows trained parameters.
User may:
- Apply to Model, which updates the current model with trained coefficients.
- Save, which save a modeling result for later review, version tracking applying to a model or running model analysis plots.
- Cancel, which closes this window, but takes no action.
User may leave training view open, let it continue to train until auto-stop criteria are reached and note that during training intermittent results are stored so user may open and review or save results from different epochs.
Training Error History Plot
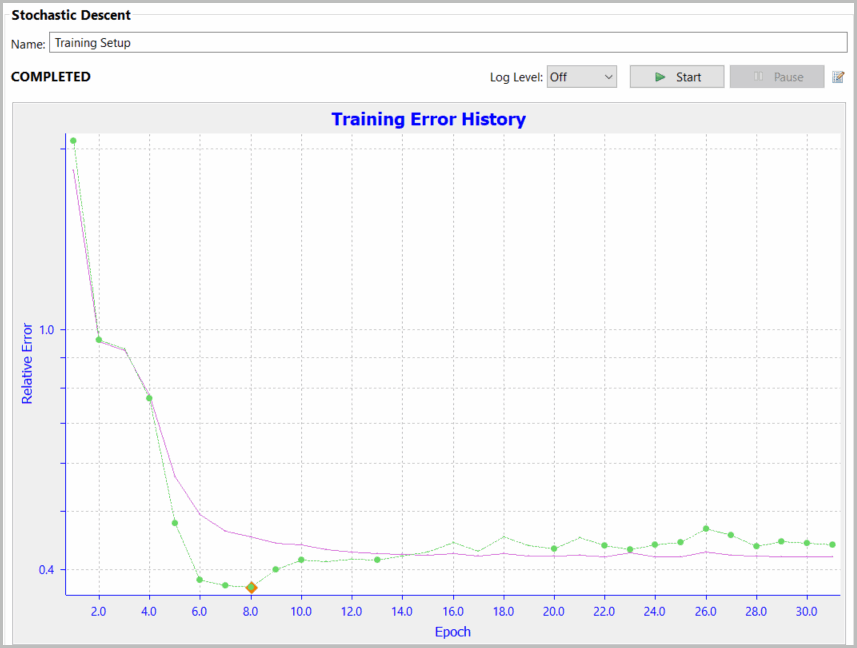
On the Training Error History Plot several items are presented with the x-axis being the training Epoch.
Provide Feedback